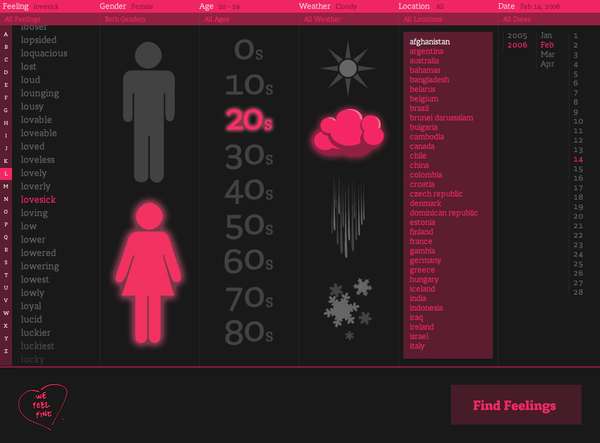
Another user generated content trend – but, unlike those recorded to date, it doesn't involve active consumer participation. The “we feel fine†team use already created content and record shifts in human emotions across the globe. So if you want to understand how London was feeling at the time of 7/7 you can slice and dice their database for a reading.
At the core of We Feel Fine is a data collection engine that automatically scours the Internet every ten minutes, harvesting human feelings from a large number of blogs. We Feel Fine scans blog posts for occurrences of the phrases "I feel" and "I am feeling". Once a sentence containing "I feel" or "I am feeling" is found, the system looks backward to the beginning of the sentence, and forward to the end of the sentence, and then saves the full sentence in a database. Once saved, the sentence is scanned to see if it includes one of about 5,000 pre-identified "feelings". If a valid feeling is found, the sentence is said to represent one person who feels that way.
If an image is found in the post, the image is saved along with the sentence, and the image is said to represent one person who feels the feeling expressed in the sentence.
Because a high percentage of all blogs are hosted by one of several large blogging companies the URL format of many blog posts can be used to extract the username of the post's author and thus the user's profile page obtaining age, gender, country, state, and city of the blog's owner. Given the country, state, and city, they can then retrieve the local weather conditions for that city at the time the post was written.
This process is repeated automatically every ten minutes, generally identifying and saving between 15,000 and 20,000 feelings per day. The data is stored in a database, and can be queried in any number of ways.
They have also developed a montage section to answer questions like: what does sadness look like? Happiness? Loneliness? The Montage presents the feelings from a given population that contain photographs and combines the associated sentence, along with any information about the sentence's author. Viewers can save, download, email to friends or print as postcards.
How long before the database is big enough to understand how people feel about brands – particularly in light of bad publicity / scandals. It could become an interesting marketing tool:
Key Themes Behind This Trend
- Global Shifts in Human Emotion
- Disruptive innovation opportunity: Using data from global shifts in human emotion to inform marketing strategies and brand perception.
- User-generated Content Analysis
- Disruptive innovation opportunity: Developing software that can analyze user-generated content for insights into consumer behavior and sentiment.
- Emotion-based Data Collection
- Disruptive innovation opportunity: Creating automated systems that collect and analyze data on human emotions from various online sources.
Where This Applies
- Market Research
- Disruptive innovation opportunity: Utilizing emotion-based data collection methods to revolutionize the way market research is conducted and consumer insights are obtained.
- Social Media Analytics
- Disruptive innovation opportunity: Developing advanced algorithms and tools that can analyze online content, including blog posts, for understanding global shifts in human emotions.
- Digital Marketing
- Disruptive innovation opportunity: Leveraging emotion-based data to create targeted and personalized digital marketing campaigns that resonate with consumers on a deeper emotional level.